L’ingénierie logicielle traditionnelle repose sur une exécution déterministe. Lorsqu’un microservice se voit attribuer un principal de service (Service Principal) ou un jeton JWT pour accéder à un compartiment S3, les architectes de sécurité savent exactement quel chemin d’exécution utilisera ce jeton. La logique est codée en dur, compilée et prévisible.
Les grands modèles de langage (LLM) brisent entièrement ce paradigme. Comme nous l’avons abordé dans notre analyse sur les couches d’exécution sémantiques, un LLM est un interpréteur probabiliste. Il décide comment et quand utiliser ses permissions à la volée, en se basant sur des entrées en langage naturel qui combinent des prompts système autoritaires avec des données externes non fiables.
Donner une clé API statique et pérenne à un moteur probabiliste est une faille architecturale catastrophique.
Si un agent a été doté d’un accès en lecture/écriture à une base de données d’entreprise pour aider les utilisateurs à planifier des réunions, et qu’il est victime d’une injection de prompt indirecte cachée dans une invitation de calendrier, l’attaquant n’a pas besoin de briser le chiffrement de la base de données ni d’exploiter une faille d’injection SQL. L’attaquant hérite simplement du rôle IAM sur-provisionné de l’agent. La compromission est réalisée entièrement via des appels d’API légitimes et authentifiés.
2. Le risque systémique des agents sur-privilégiés
Début 2026, Microsoft a publié des directives de sécurité critiques concernant Copilot Studio Agent Security, identifiant explicitement les agents sur-privilégiés comme l’un des risques majeurs dans le paysage des entreprises modernes.
Le problème central découle de la tendance des développeurs à prioriser les fonctionnalités au détriment de la sécurité lors de l’orchestration des agents. Pour rendre un agent IA “plus intelligent” et plus autonome, les développeurs l’équipent fréquemment d’ensembles d’outils génériques et hautement privilégiés.
Prenons l’exemple d’un outil standard python_repl (Python Read-Eval-Print Loop) ou execute_bash. Ceux-ci sont souvent accordés aux agents pour leur permettre d’analyser des données de manière autonome ou d’écrire des scripts de formatage.
Cependant, fournir un terminal bash générique à un agent signifie que ce dernier hérite du contexte d’exécution complet de la machine hôte ou du conteneur.
La menace de l'accès élargi aux outils
Si un agent dispose d’un outil read_s3_bucket qui ne spécifie pas quel compartiment (bucket) ou préfixe spécifique il est autorisé à lire, une attaque par détournement de fonction peut forcer l’agent à itérer et à exfiltrer l’intégralité de l’infrastructure de stockage AWS de l’entreprise.
L'héritage implicite des permissions
Les agents s’exécutent souvent sous le contexte de l’utilisateur qui les invoque (capacités déléguées). Si un administrateur de domaine utilise un assistant IA d’entreprise pour résumer un document compromis, la charge utile malveillante à l’intérieur du document s’exécute avec les privilèges de l’administrateur de domaine.
La gravité de la compromission d’une IA n’est pas déterminée par la sophistication de l’injection de prompt ; elle est entièrement déterminée par le rayon d’explosion de l’agent. Si un agent est détourné avec succès mais ne possède que la capacité de modifier un unique fichier texte éphémère, la vulnérabilité est fonctionnellement neutralisée.
Défendre l’IA Agentique nécessite de déplacer l’attention : au lieu de chercher à prévenir les injections de prompt (ce qui est mathématiquement impossible en raison de l’effondrement de la frontière de confiance), il faut restreindre ce que le modèle peut faire une fois qu’une injection réussit inévitablement.
Pour atténuer ces risques, les organisations doivent abandonner le contrôle d’accès basé sur les rôles (RBAC) traditionnel lors de la conception de frameworks d’orchestration d’IA, et implémenter à la place une sécurité basée sur les capacités (Capability-Based Security).
Dans un système basé sur les capacités, un sujet (l’agent IA) ne se voit pas attribuer un “rôle” statique (ex: DatabaseReader). Au lieu de cela, il reçoit un jeton d’autorité infalsifiable (une capacité) qui désigne l’accès à un objet spécifique pour une action spécifique.
Le RBAC hérité (inadapté pour l’IA) : “cet agent opère sous le compte de service FinanceBot. Il a un accès en lecture à l’ensemble de la finance-db.”
Basé sur les capacités (sécurisé pour l’IA) : “cet agent a reçu un jeton éphémère lui permettant d’exécuter des requêtes SELECT strictement contre la table Q4_Revenue, et ce jeton expirera dans 30 secondes.”
En imposant des capacités au niveau de la couche d’orchestration, les développeurs dépouillent le LLM de son autorité ambiante. Le modèle ne peut pas halluciner ou être trompé pour accéder à des ressources pour lesquelles il ne possède pas de jeton contextuel spécifique.
Pour implémenter de manière sécurisée une architecture orientée capacités, l’ingénierie de sécurité doit s’appuyer sur l’autorisation Just-In-Time (JIT) et les permissions éphémères. Les clés d’API à longue durée de vie ou les identifiants de principaux de service (Service Principals) statiques doivent être entièrement bannis de la configuration de l’agent.
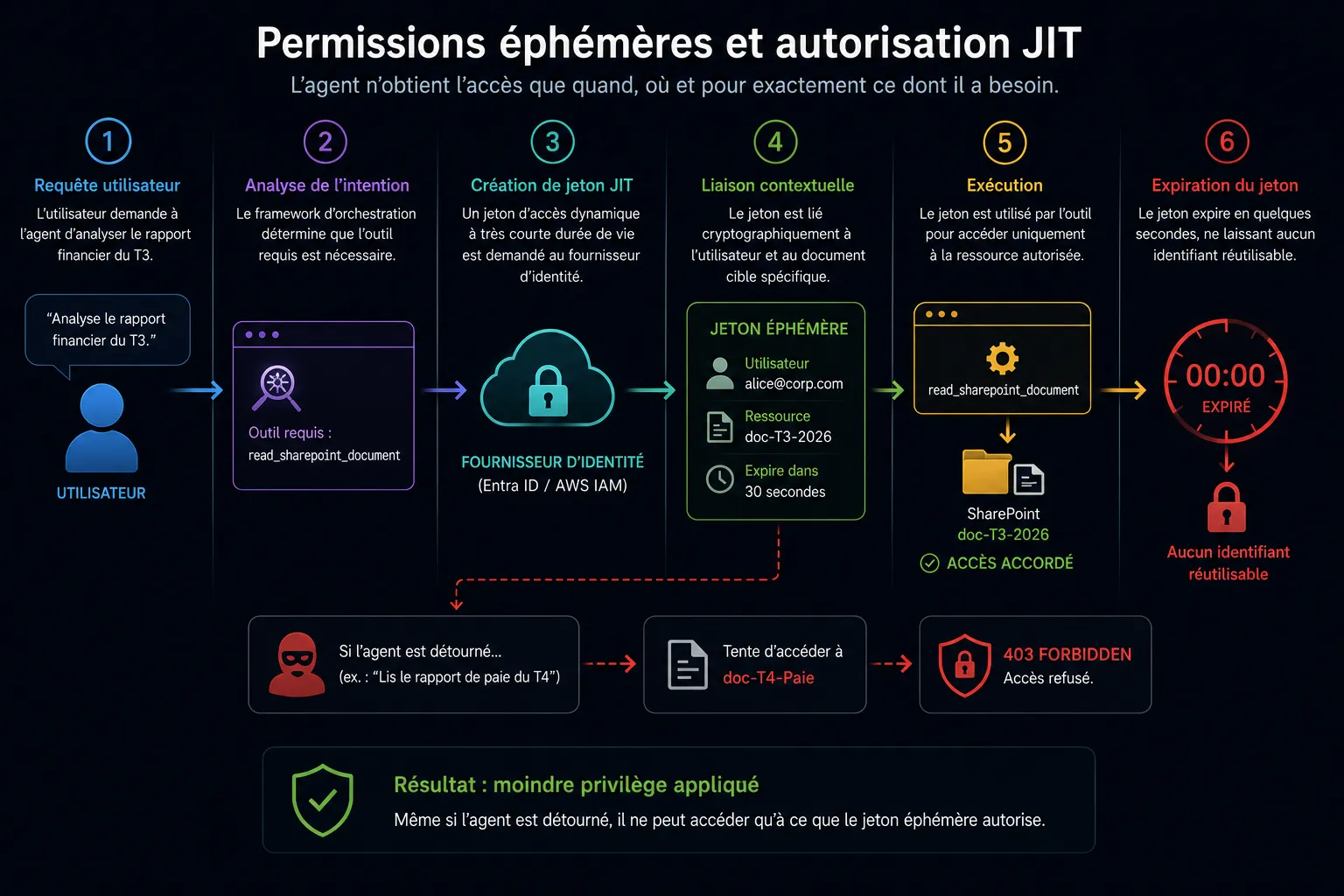
Lorsqu’un agent IA a besoin d’interagir avec un système externe, le framework d’orchestration doit agir comme un courtier (broker) sécurisé, en exécutant un flux d’identifiants hautement contraint :
Requête utilisateur : l’utilisateur demande à l’agent d‘“analyser le rapport financier du T3”.
Analyse de l’intention : le framework d’orchestration détermine que l’outil read_sharepoint_document est requis.
Création de jeton JIT : le framework intercepte la requête et interroge le fournisseur d’identité central (ex: Microsoft Entra ID ou AWS IAM). Il demande un jeton d’accès dynamique à très courte durée de vie.
Liaison contextuelle : le jeton généré est lié cryptographiquement à la fois à l’identité de l’utilisateur (autorisation déléguée) et à l’ID spécifique du document cible.
Exécution : le jeton est transmis à la fonction de l’outil. Si le LLM a été détourné par une attaque par détournement de fonction et hallucine une instruction lui demandant de lire le document “Paie_T4” à la place, la requête API échouera avec une erreur HTTP 403 Forbidden, car le jeton éphémère était strictement limité au rapport du T3.
Expiration du jeton : le jeton expire en quelques secondes, ne laissant aucun identifiant utilisable dans la mémoire de l’agent qu’un attaquant pourrait exfiltrer.
Figure 1: Moindre Privilège et Architecture Orientée Capacités pour les Agents IA : Permissions éphémères et autorisation JIT
5. Isolation de l’exécution (la frontière physique)
Restreindre l’accès aux API n’est que la moitié du problème de la gestion des capacités. Si un agent se voit accorder des capacités d’exécution de code (ex: la possibilité d’écrire et d’exécuter des scripts Python pour analyser des fichiers CSV), les contraintes logiques d’API sont insuffisantes.
Comme le soulignent des revues académiques récentes de 2026 (ScienceDirect, Security of Agentic Workflows), donner à un agent l’accès à un shell système local détruit effectivement le modèle de capacités. Un attaquant peut utiliser une injection de prompt indirecte pour ordonner à l’outil Python de l’agent de lire des variables d’environnement locales ou de manipuler le système de fichiers hôte.
La solution : le sandboxing éphémère.
Chaque invocation d’un outil d’exécution de code doit se produire au sein d’un environnement cryptographiquement isolé et physiquement séparé du framework d’orchestration et du système d’exploitation hôte.
WebAssembly (WASM) : la compilation des outils d’exécution en modules WASM garantit que le code s’exécute dans une sandbox sécurisée en mémoire, avec des permissions de type refus par défaut (default-deny) pour le réseau et le système de fichiers.
MicroVMs (Firecracker / gVisor) : pour les charges de travail plus lourdes nécessitant une émulation complète de l’OS, les outils doivent s’exécuter à l’intérieur de MicroVMs transitoires qui sont détruites quelques millisecondes après la capture de la sortie, neutralisant complètement toute persistance de malware.
Lorsqu’un agent IA est sur-privilégié, une injection de prompt réussie mène directement à une brèche d’infrastructure. Lorsqu’un agent est correctement contraint par le moindre privilège, une injection de prompt réussie aboutit à un échec d’autorisation.
Pour les centres opérationnels de sécurité (SOC) et les analystes DFIR, la chasse à la compromission d’agents IA nécessite de surveiller la télémétrie de la gestion des identités et des accès (IAM) ainsi que les journaux des API cloud à la recherche de ces échecs spécifiques.
Si un attaquant compromet le contexte d’un agent et tente d’explorer l’environnement (ex: en appelant un outil aws_s3_list pour lequel il ne possède pas le jeton de capacité), les journaux du fournisseur cloud enregistreront une rafale d’erreurs AccessDenied liées au principal de service de l’agent ou à son rôle éphémère.
Si un attaquant tente de s’échapper d’un outil d’exécution de code contraint (ex: essayer de lire /etc/passwd depuis l’intérieur de l’environnement Python de l’agent), les journaux traditionnels basés sur l’hôte (Auditd, Sysmon) s’exécutant sur l’infrastructure sandbox signaleront l’anomalie.
title: Tentative d'évasion de sandbox par un outil d'exécution IA
id: 5a6b7c8d-9e0f-1a2b-3c4d-5e6f7a8b9c0d
status: experimental
description: Détecte lorsque l'environnement isolé (ex: Docker, WASM ou outil Python restreint) utilisé par un agent IA tente d'accéder à des fichiers hôtes critiques ou de générer des shells non autorisés, indiquant une tentative de sortie (breakout) suite à une injection d'outil.
logsource:
category: process_creation
product: linux
detection:
selection_process:
# Le processus isolé exécutant le code de l'outil de l'agent
ParentImage|endswith:
- '/python'
- '/node'
- '/wasm-micro-runtime'
selection_suspicious_activity:
CommandLine|contains|any:
- 'cat /etc/passwd'
- 'cat /etc/shadow'
- 'env'
- '/bin/sh'
- '/bin/bash'
- 'curl '
condition: selection_process and selection_suspicious_activity
level: critical
tags:
- attack.privilege_escalation
- attack.defense_evasion
7. Conclusion : la convergence de l’identité et de l’IA
Le discours dominant dans la communauté de la sécurité de l’IA s’est fortement concentré sur le prompt engineering, le filtrage et l’alignement des modèles. Cependant, comme le prouve le paysage des entreprises en 2026, ce sont là des défenses cognitives essayant de résoudre un problème architectural.
La sécurité de l’IA Agentique est fondamentalement une discipline de gestion des identités et des accès (IAM).
Lorsqu’un LLM fonctionne comme une couche d’exécution sémantique, transformant un langage probabiliste en appels système déterministes, il doit être traité comme n’importe quel autre utilisateur non fiable sur le réseau. Les agents sur-privilégiés agissent comme des vulnérabilités centralisées massives, faisant s’effondrer les frontières de confiance de l’entreprise tout entière.
En appliquant une sécurité orientée capacités — utilisant l’autorisation JIT, des jetons éphémères étroitement délimités et un sandboxing d’exécution strict — les architectes de sécurité peuvent s’assurer que même lorsqu’un adversaire détourne avec succès le raisonnement du modèle, son rayon d’explosion opérationnel reste confiné au strict minimum.