Pendant des décennies, l’investigation numérique s’est concentrée sur le stockage non volatil (les disques) et la mémoire volatile principale (la RAM du CPU). Les plateformes de détection et de réponse des terminaux (EDR) accrochent (hook) les API du noyau dans l’OS hôte pour surveiller les allocations de mémoire (ex: VirtualAllocEx).
Cependant, lorsqu’une entreprise déploie un grand modèle de langage (LLM) à l’aide de frameworks comme PyTorch ou vLLM, les opérations mathématiques et les données de contexte sont immédiatement déchargées via le bus PCIe vers la mémoire vidéo du GPU (VRAM).
Comme le souligne la recherche DiVA Portal de 2025 sur la détection de l’utilisation des LLM dans l’investigation numérique de la mémoire principale, une fois que les données entrent dans le GPU, elles échappent totalement aux radars. Pour enquêter sur une injection de prompt indirecte ou une attaque par détournement de fonction visant un agent autonome, les analystes doivent extraire la “mémoire à court terme” de l’IA : le cache KV.
Pour générer du texte efficacement, les LLM autorégressifs utilisent un cache Key-Value (KV).
Au lieu de recalculer la matrice d’attention pour l’ensemble du prompt à chaque fois qu’un nouveau jeton (token) est généré, le modèle sauvegarde les tenseurs Key et Value calculés pour les jetons précédents directement dans la mémoire du GPU.
Dans les moteurs d’inférence hautement optimisés comme vLLM, la gestion de ce cache massif constitue le principal goulot d’étranglement. Pour résoudre la fragmentation de la mémoire, ces moteurs ont introduit PagedAttention (inspiré de la pagination de la mémoire virtuelle des systèmes d’exploitation).
Le cache KV est divisé en blocs de taille fixe. Lorsqu’un utilisateur génère un prompt, le moteur alloue dynamiquement des blocs non contigus de VRAM pour stocker les jetons.
La faille architecturale
pour des raisons de performances, lorsqu’une séquence de génération se termine ou est annulée, le moteur d’inférence se contente de “dissocier” (unlink) le bloc du pool de mémoire active. Il ne met pas les données à zéro. Les données brutes des tenseurs représentant le prompt de l’utilisateur restent physiquement présentes dans le bloc de VRAM jusqu’à ce qu’elles soient écrasées par une nouvelle requête.
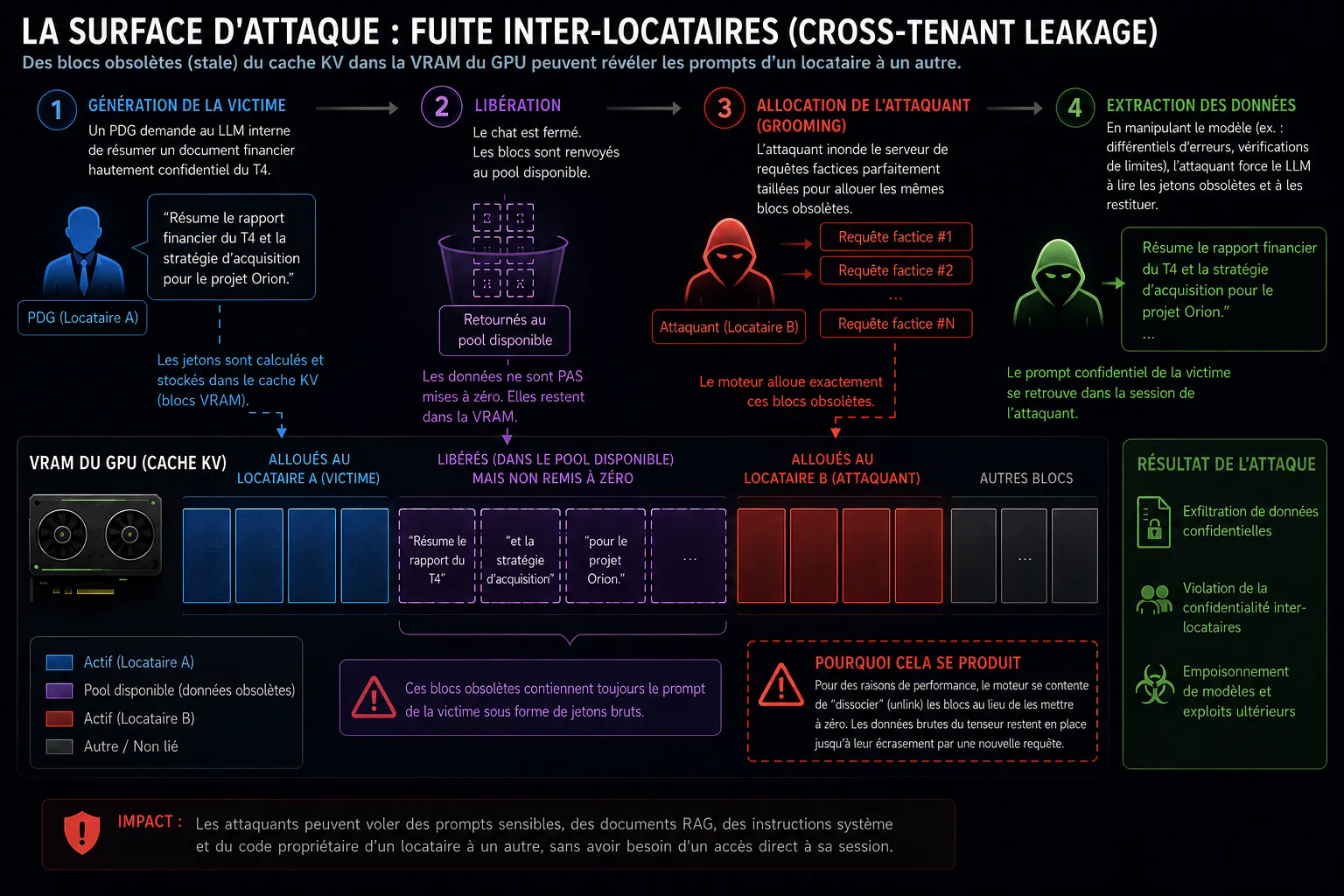
3. La surface d’attaque : fuite inter-locataires (Cross-Tenant Leakage)
Ce recyclage de mémoire agressif et non sécurisé crée une surface d’attaque dévastatrice dans les environnements IA cloud multi-locataires ou les clusters d’inférence d’entreprise partagés.
Comme l’a démontré l’article NDSS 2025 I Know What You Asked: Prompt Leakage via KV-Cache Sharing, et dramatiquement militarisé par la CVE-2026-7141 (RCE du cache KV vLLM), les attaquants exploitent ces blocs obsolètes (stale blocks).
Génération de la victime : un PDG demande au LLM d’entreprise interne de résumer un document financier hautement confidentiel du T4. Les jetons sont stockés dans des blocs VRAM.
Libération : le PDG ferme le chat. Les blocs sont renvoyés au pool disponible, mais contiennent toujours les données financières non chiffrées.
Allocation de l’attaquant (Grooming) : un utilisateur interne malveillant (ou un agent compromis) inonde immédiatement le serveur d’inférence de requêtes factices d’une taille parfaite pour forcer le moteur à allouer exactement ces mêmes blocs obsolètes.
Extraction des données : en utilisant des différentiels d’erreurs ou en manipulant les vérifications de limites du mécanisme d’attention, l’attaquant trompe le LLM pour qu’il “lise” les jetons obsolètes non initialisés et restitue le prompt du PDG dans la session de chat de l’attaquant.
Forensique de la Mémoire GPU et Chasse dans le Cache KV
Figure 1 : Forensique de la Mémoire GPU et Chasse dans le Cache KV, La surface d’attaque : fuite inter-locataires (Cross-Tenant Leakage)
Acquérir la mémoire du GPU lors d’un incident actif est une discipline émergente. Les outils standards comme nvidia-smi ne fournissent que des métadonnées (pourcentages d’utilisation de la VRAM, PID actifs), et non le contenu brut de la mémoire.
Pour effectuer un vidage (dump) forensique de la VRAM, les analystes doivent agir pendant que le serveur est en cours d’exécution.
La méthode la plus sûre et la plus fiable consiste à s’interfacer directement avec le framework d’inférence en cours d’exécution. Les frameworks modernes proposent des API de transfert KV distribué destinées à l’équilibrage de charge, qui peuvent être détournées pour le DFIR.
Par exemple, l’exploitation de vllm.distributed.kv_transfer permet à un analyste d’intercepter et de sérialiser les états actifs du cache KV directement dans un tableau d’octets Python, contournant ainsi la nécessité d’effectuer des lectures brutes de la mémoire PCIe.
Si le moteur ne répond pas, les équipes DFIR avancées utilisent des outils C++ personnalisés basés sur l’API CUDA (ex: en utilisant cudaMemcpy) pour lire les blocs de mémoire de l’appareil (device) et les ramener vers la RAM du CPU hôte, sauvegardant ainsi les octets bruts des tenseurs sur le disque pour une analyse hors ligne.
Que se passe-t-il si le serveur a déjà planté, ou si l’on vous remet une image disque statique ? Le cache KV est-il perdu à jamais ? Pas nécessairement.
Selon des recherches de mars 2026 (Shadow in the Cache: Unveiling Privacy Risks of KV-cache in LLM Inference), les moteurs d’inférence implémentent souvent le KV Cache Swapping (fichier d’échange) pour éviter les erreurs de mémoire insuffisante (Out-Of-Memory - OOM) lors des pics de trafic.
Lorsque la VRAM du GPU atteint 100 % de sa capacité, le moteur expulse (evicts) de force les blocs KV les moins récemment utilisés vers la RAM du CPU hôte. Si la RAM du CPU se remplit à son tour, le noyau Linux paginera cette mémoire directement sur le disque dur, dans le fichier /swapfile ou la partition de swap.
Le pivot DFIR :
Les “pensées” du LLM ont désormais fuité sur le stockage non volatil.
Puisque les jetons des LLM sont souvent directement corrélés à du texte, les analystes peuvent utiliser des outils standards d’extraction de chaînes (carving) contre la partition d’échange du serveur IA pour récupérer les prompts divulgués.
carve_swap_for_prompts.sh
# Extraction de la partition d'échange Linux à la recherche de charges utiles connues d'injection de prompt ou de données sensibles
# en utilisant bstrings d'Eric Zimmerman ou un grep natif
La détection de la manipulation malveillante du cache KV nécessite de surveiller les journaux d’erreurs du moteur d’inférence. Lorsque les attaquants forcent le moteur à lire des blocs de cache non initialisés ou mal formés (comme vu dans l’exploit RCE de la CVE-2026-7141), les mathématiques des tenseurs se brisent.
Les analystes doivent chasser les anomalies mathématiques des tenseurs.
Alors que l’Intelligence Artificielle s’intègre profondément dans les infrastructures d’entreprise, l’investigation numérique doit évoluer au-delà du CPU et du disque dur.
Le GPU n’est plus seulement un accélérateur mathématique ; c’est l’enclave de données la plus sensible du centre de données moderne. Le cache KV représente une surface d’attaque massive et non protégée où des prompts sensibles, des documents RAG et des charges utiles adverses résident dans des formats bruts et non chiffrés.
Tant que les frameworks d’inférence n’implémenteront pas d’enclaves de mémoire sécurisées (Confidential Computing pour les GPU) et de mise à zéro cryptographique des blocs VRAM libérés, les analystes DFIR doivent impérativement maîtriser l’acquisition de la mémoire GPU et l’extraction des fichiers d’échange (swap) pour répondre efficacement à la prochaine génération de cyberattaques IA.