For decades, digital forensics has focused on non-volatile storage (disks) and primary volatile memory (CPU RAM). Endpoint Detection and Response (EDR) platforms hook kernel APIs in the host OS to monitor memory allocations (VirtualAllocEx).
However, when an enterprise deploys a Large Language Model (LLM) using frameworks like PyTorch or vLLM, the mathematical operations and the context data are immediately offloaded across the PCIe bus to the GPU’s Video RAM (VRAM).
As highlighted in the 2025 DiVA Portal research on Detecting LLM usage in primary memory digital forensics, once data enters the GPU, it effectively falls off the map. To investigate an Indirect Prompt Injection or a Function Hijacking Attack on an autonomous agent, analysts must extract the AI’s “short-term memory”: the KV Cache.
To generate text efficiently, autoregressive LLMs utilize a Key-Value (KV) Cache.
Instead of recomputing the attention matrix for the entire prompt every time a new token is generated, the model saves the computed Key and Value tensors of previous tokens in the GPU memory.
In highly optimized serving engines like vLLM, managing this massive cache is the primary bottleneck. To solve memory fragmentation, engines introduced PagedAttention (inspired by OS virtual memory paging).
The KV Cache is divided into fixed-size blocks. As a user generates a prompt, the engine dynamically allocates non-contiguous blocks of VRAM to store the tokens.
The Architectural Flaw
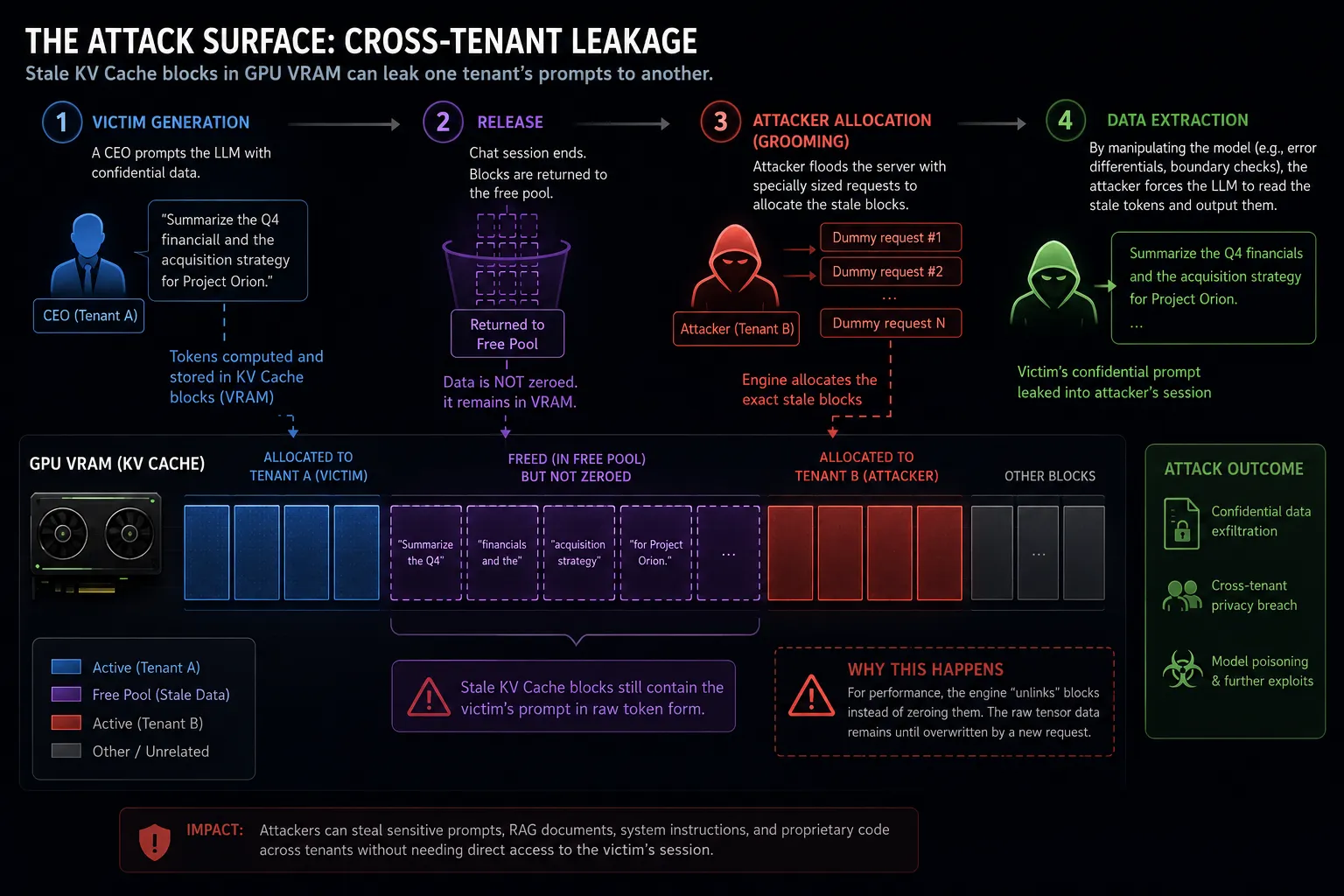
For performance reasons, when a generation sequence finishes or is aborted, the serving engine simply “unlinks” the block from the active memory pool. It does not zero out the data. The raw tensor data representing the user’s prompt remains physically present in the VRAM block until it is overwritten by a new request.
This aggressive, unsafe memory recycling creates a devastating attack surface in multi-tenant cloud AI environments or shared corporate inference clusters.
As demonstrated in the NDSS 2025 paper I Know What You Asked: Prompt Leakage via KV-Cache Sharing, and dramatically weaponized in CVE-2026-7141 (vLLM KV Cache RCE), attackers exploit these stale blocks.
Victim Generation: A CEO prompts the internal corporate LLM to summarize a highly confidential Q4 financial document. The tokens are stored in VRAM blocks.
Release: The CEO closes the chat. The blocks are returned to the free pool, containing the unencrypted financial data.
Attacker Allocation (Grooming): A malicious internal user (or a compromised agent) immediately floods the inference server with perfectly sized dummy requests to force the engine to allocate those exact stale blocks.
Data Extraction: By utilizing error-differentials or manipulating the attention mechanism’s boundary checks, the attacker tricks the LLM into “reading” the uninitialized, stale tokens and outputting the CEO’s prompt into the attacker’s chat session.
GPU Memory Forensics & Hunting in the KV Cache
Figure 1 : GPU Memory Forensics & Hunting in the KV Cache, the Attack Surface: Cross-Tenant Leakage
Acquiring GPU memory during an active incident is an emerging discipline. Standard tools like nvidia-smi only provide metadata (VRAM utilization percentages, active PIDs), not the raw memory contents.
To perform a forensic VRAM dump, analysts must act while the server is running.
The safest and most reliable method is to interface directly with the running inference framework. Modern frameworks offer distributed KV transfer APIs intended for load balancing, which can be repurposed for DFIR.
For example, leveraging vllm.distributed.kv_transfer allows an analyst to intercept and serialize the active KV cache states directly into a Python byte array, bypassing the need for raw PCIe memory reads.
If the engine is unresponsive, advanced DFIR teams utilize custom C++ tools built on the CUDA API (e.g., using cudaMemcpy) to read device memory blocks back to the host CPU RAM, saving the raw tensor bytes to disk for offline analysis.
What if the server has already crashed, or you are handed a static disk image? Is the KV Cache lost forever? Not necessarily.
According to March 2026 research (Shadow in the Cache: Unveiling Privacy Risks of KV-cache in LLM Inference), inference engines often implement KV Cache Swapping to prevent Out-Of-Memory (OOM) errors during traffic spikes.
When the GPU VRAM hits 100% capacity, the engine forcefully evicts the least recently used KV blocks to the host’s CPU RAM. If the CPU RAM also fills up, the Linux kernel will page this memory directly onto the hard drive within the /swapfile or swap partition.
The DFIR Pivot:
The “thoughts” of the LLM have now leaked onto non-volatile storage.
Because LLM tokens often correlate directly to text, analysts can use standard string-carving tools against the swap partition of the AI server to recover the leaked prompts.
carve_swap_for_prompts.sh
# Carving the Linux swap partition for known prompt injection payloads or sensitive data
Detecting malicious manipulation of the KV Cache requires monitoring the inference engine’s error logs. When attackers force the engine to read uninitialized or malformed cache blocks (as seen in the CVE-2026-7141 RCE exploit), the tensor mathematics break.
As Artificial Intelligence becomes deeply integrated into enterprise infrastructure, digital forensics must evolve beyond the CPU and the hard drive.
The GPU is no longer just a mathematical accelerator; it is the most sensitive data enclave in the modern data center. The KV Cache represents a massive, unprotected attack surface where sensitive prompts, RAG documents, and adversarial payloads reside in raw, unencrypted formats.
Until inference frameworks implement secure memory enclaves (Confidential Computing for GPUs) and cryptographic zeroing of released VRAM blocks, DFIR analysts must proactively master GPU memory acquisition and swap-file carving to effectively respond to the next generation of AI breaches.